
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- K8S
- Deployment
- cpu
- elasticsearch
- Service
- AZ-104
- terraform
- RBAC
- kernel
- IAM
- AWS
- AZ-900
- Role
- ansible
- FastAPI
- leetcode
- Django
- AZURE
- ebs
- asyncio
- asgi
- IAC
- Kubernetes
- 자바스크립트
- Network
- docker
- DevOps
- EC2
- POD
- Python
- Today
- Total
궁금한게 많은 개발자 노트
[ Database ] Elasticsearch vs RDBMS 본문

RDBMS는 잘 알려져있듯 관계형 데이터베이스 관리 시스템을 의미합니다.
그렇다면 Elasticsearch는 무엇이고, 언제 사용하며 왜 RDBMS와 비교되는지 알아보고자 합니다.
Elasticsearch는 Apache Lucene(아파치 루씬: 정보 검색 라이브러리) 기반 java 오픈 소스 분산 검색 엔진입니다.
HTTP 웹 인터페이스와 스키마에서 자유로운 JSON 문서와 함께 분산 멀티테넌트(하나의 소프트웨어 인스턴스로 여러 사용자에게 서비스를 제공) 지원 전문 검색 엔진을 제공합니다.
데이터 저장소가 아니라 데이터 베이스를 대체할 수 없지만, 방대한 양의 데이터를 신속하고 거의 실시간으로 저장, 검색, 분석할 수 있는 엔진입니다. 데이터베이스에서도 데이터의 조회가 가능한데, 왜 검색 엔진이 필요할까요?
[ 장점 ]
- DBMS는 단순 텍스트 매칭에 의한 검색만을 제공합니다.
최신 RDBMS는 full-text검색을 지원하지만, 대부분의 RDBMS는 이를 지원하지 않습니다. 반면 Elasticsearch는 Lucene을 기반으로 구축되기 때문에 n-gram기반 full-text검색을 지원합니다. 여러 단어로 변형하거나 동의어/유의어에 근거한 검색도 가능하고 여러 플러그인으로 형태소 기반 자연어 처리도 가능합니다.
- 비정형 데이터
전통적인 DB에서는 처리하기 어려운 대용량, 비정형 데이터 검색이 가능합니다. 데이터 저장소의 역할을 완전히 대신할 수는 없지만 MongoDB 같은 대용량 스토리지처럼 사용도 가능합니다.
비정형 데이터의 한 예로 Log가 있습니다. 비정형 로그 데이터는 수집하는 것만으로 끝나지 않고 분석하여 logstash, kibana등과 같이 사용하여 로그 데이터를 수집하고 분석/시각화할 수 있습니다. (빅데이터 처리의 장점)
- 빠른 성능
Elasticsearch는 또한 거의 실시간 검색 플랫폼입니다. 이것은 문서가 색인될 때부터 검색 가능해질 때까지의 대기 시간이 아주 짧다는 뜻입니다. 이 대기 시간은 보통 1초입니다. 결과적으로, Elasticsearch는 보안 분석, 인프라 모니터링 같은 시간이 중요한 사용 사례에 이상적입니다. 또한, 역색인 구조를 바탕으로 빠른 검색 속도 보장합니다.
Real-time으로 동작하지는 않으며, 1초의 시간에는 색인된 데이터가 내부적으로 commit, flush과정을 거치기 때문입니다.
- 분산 처리
Elasticsearch의 저장된 문서는 샤드라고 하는 여러 다른 컨테이너에 걸쳐 분산되며, 이 샤드는 복제되어 하드웨어 장애 시에 중복되는 데이터 사본을 제공합니다. 이러한 분산적인 특징 덕분에 광범위한 서버 확장과 대용량 데이터를 처리할 수 있께 해줍니다.
[ 단점 ]
- Transaction과 Rollback의 부재
분산 시스템의 구성적 특징 때문에, 시스템적으로 비용 소모가 큰 트랜잭션, 롤백 기능을 지원하지 않습니다.
그로 인해 데이터 관리에 유의하여야 합니다.
- 진정한 의미의 없데이트 지원X
Elasticsearch는 UPDATE명령이 존재하지만, 진정한 의미의 업데이트를 지원하지 않습니다. 무슨 의미인가 하면 기존 데이터를 변경하는 것이 아닌, 기존 데이터를 삭제하고 변경하고자 하는 데이터를 새로 만드는 과정으로 업데이트됩니다.
이러한 특성은 데이터 불변성(Immutable)이라는 이점을 제공하기도 합니다.
Elasticsearch와 RDBMS의 차이
- 데이터 CRUD 방식의 차이
RDBMS의 경우 CRUD을 위해 클라이언트에서 관계형 DB서버에 연결을 하고 SQL을 보내는 방식입니다.
(SELECT, INSERT, DELETE, UPDATE등)
Elasticsearch에서는 Restful API를 사용합니다. HTTP 통신에서 사용하는 GET, POST, PUT, DELETE등의 메소드가 그대로 적용되어 사용됩니다. 하지만 데이터 삽입인 POST의 경우 RDBMS와 다른 특성을 가지는데, 스키마가 미리 저장되어 있지 않더라도 자동으로 필드를 생성하고 저장한다는 점입니다. 이러한 특징은 큰 유연성을 제공하지만 또 다른 문제를 야기할 수 있습니다.

- 용어 차이
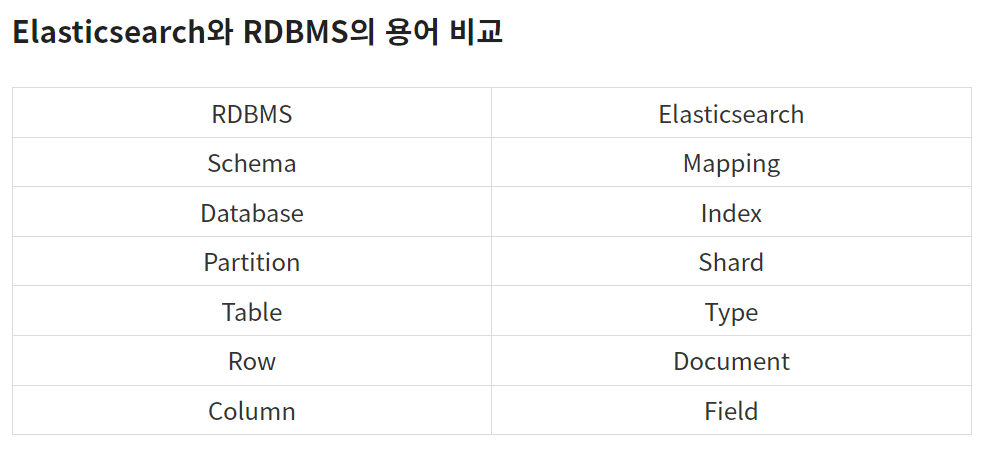
- Schemaless
기존 RDBMS는 스키마라는 구조에 따라 데이터를 적합한 형태로 변형하여 저장 및 관리하지만, Elasticsearch는 비정형의 다양한 형태의 문서도 자동으로 색인, 검색이 가능하다는 특징이 있습니다.
- Multi tenancy
Elasticsearch에서 인덱스는 위에서 볼 수 있듯 RDBMS의 Database와 같은 개념입니다. 하지만 Elasticsearch에서는 서로 다른 데이터베이스에서도 검색할 필드명이 존재한다면 여러 개의 데이터베이스를 한번에 조회할 수 있습니다.
'Back End' 카테고리의 다른 글
| [ Python] aiobotocore를 사용한 AWS S3와 연동 (0) | 2024.02.08 |
|---|---|
| [ FastAPI ] 비동기 메커니즘 (0) | 2023.12.11 |
| [ Architecture ] Microservice와 Monolithic (0) | 2023.07.22 |
| [ Python ] FastAPI에 대한 이해 (0) | 2023.07.17 |
| [ Python ] Django에 대한 이해 (0) | 2023.07.17 |
