
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- AZURE
- ebs
- Network
- Role
- Django
- K8S
- AZ-104
- AZ-900
- POD
- asgi
- docker
- DevOps
- FastAPI
- ansible
- IAM
- Python
- leetcode
- terraform
- Service
- EKS
- Kubernetes
- RBAC
- IAC
- dockerfile
- EC2
- Deployment
- asyncio
- 자바스크립트
- AWS
- elasticsearch
- Today
- Total
궁금한게 많은 개발자 노트
[ Kubernetes ] CPU 알뜰하게 사용하기 본문
비용을 줄이는 것에는 많은 방법이 있지만 서버의 비용을 최적화하는 것이 가장 대표적인 방법일 수 있습니다.
쿠버네티스는 여러 서버에서 컨테이너를 실행, 관찰, 제어할 수 있는 도구로 CPU할당량에 대한 설정도 가능합니다.
CPU Request를 통해 최소한으로 사용 가능한 자원을 설정할 수 있고, CPU Limits를 통해 최대 허용량을 설정할 수 있습니다. 최대 허용량보다 많이 사용하려 할 때 CPU Throttling이 발생하며 CPU를 할당받지 못해 대기하는 현상을 말합니다.
자원 최적화를 통해 비용을 줄일 수 있지만, 비용을 줄이면서도 서비스 안정성을 유지해야 하는 것이 가장 중요합니다. 이를 위해서는 꼭 필요한 만큼만 자원을 할당해야 하며 이는 비용과도 직결됩니다. 그리고 필요한 자원 사용량도 최소화하고 분산시킨다면 원하는 자원의 최적화를 이룰 수 있지 않을까 싶습니다.
이제 어떻게하면 위에서 설명한 방안대로 kubernetes에서 CPU 자원을 최적화 할 수 있는 지에 대해 알아보고자 합니다.
- CPU Throttling 방지
- CPU Requests/Limits 최소화
- CPU 사용량 최소화
- CPU 사용량 분산
CPU자원을 최적화하기 위해 위와 같은 방안을 마련해야 할 것 같습니다. 먼저 CPU Throttling을 방지하기 위해서는 어떻게 해야할 지 알아보려 합니다. CPU지표를 보면 CPU 사용량 추이가 Limits보다 낮아도 Throttling이 발생하는 경우가 있습니다. 이 현상은 왜 발생하는 것일까요? 이해하기 위해서는 CFS에 대해 알아보면 좋을 것 같습니다.
https://www.kernel.org/doc/html/latest/scheduler/sched-design-CFS.html
CFS(Completely Fair Scheduler)는 컨테이너가 워커 노드의 CPU를 공유하기 위해 사용하는 CPU Scheduler입니다. 각각의 컨테이너는 자기가 실행하고 있는 워커노드의 모든 CPU를 사용하며, time slice를 할당량을 cgroup v2의 cpu.weight 값 기반(cgroup v1의 cpu.shares)으로 비율을 측정하여 나눠서 분배받습니다.
CFS의 동작에는 period와 quota라는 것이 있습니다. 일정 기간동안 얼마나 사용할 지를 미리 정해두고 그것보다 기준 시간에 많이 사용하려 하면 throttling이 발생하게 되는 것입니다. limits를 설정하게 되면 limits가 넘는 지 주기적으로 확인하는데 100ms period동안 할당량이 50%를 사용하는 컨테이너는 그 이상 사용하려 할 때는 대기해야 하며 이 때 throttling이 발생하는 것 입니다.

간단히 설명해보면, kubernetes에서 pod내 존재하는 container배포 시 설정하는 cpu resource설정에는 requests와 limits가 있으며 requests는 container가 사용하는 최소 사용량을 나타내며, limits는 최대 허용량을 나타냅니다.
requests는 위에서 말씀드린 것처럼 cgroup의 cpu.weight를 통해 설정되며 kubernetes가 cpu requests로 전달된 값을 상대적으로 변환하여 전체 워커 노드에서 사용 가능한 cpu를 전달된 weight의 비율로 나눠 컨테이너에 할당해주어 최소 자원을 보장하는 방식입니다.
이제 limits에 대해 알아보겠습니다. limits는 앞서 말했듯 period와 quota로 설정되는데 kubernetes에서는 cpu.cfs_period_us값을 100000us(=100ms)로 할당합니다. 1cpu = 1000 millicore이므로 결론적으로는 cpu.limits로 전달된 값을 milicore로 환산하고 100을 곱해 quota값을 구할 수 있습니다. 예를 들어 cpu.limits를 3으로 할당했다면 milicore로 환산하면 3000m이고 이에 100을 곱해 300000us가 cpu.cfs_quota_us로 설정됩니다. 이렇게 되면 100ms동안 3개의 cpu core를 온전히 100%사용한다는 의미보다는 100ms 시간동안 사용할 수 있는 모든 cpu에서 사용된 시간의 합이 300ms라고 해석하는 것이 좋습니다. (6개의 cpu가 있는 경우 각 50%씩 사용하는 것도 가능하기 때문). 이 때 이것보다 많은 cpu시간을 사용하려 하는 경우 throttling이 발생하게 됩니다.
이제 CPU 사용량이 서비스 전체에 설정한 Limits보다 적더라도 컨테이너에서 CPU Throttling이 발생하는 이유에 대해서는 알게되었으니, 이런 현상을 완화하기 위해서는 cpu-cfs-quota-period를 살펴볼 수 있습니다.
CFS가 CPU사용량을 확인하는 간격에 대해 변경을 한다는 의미이며, 이를 100ms에서 10ms로 줄인다면 최대 throttling시간도 10ms로 줄어들게 되고, (CPU를 사용할 기회가 자주 찾아오는 반면에, 잦은 context switching으로 인해 오버헤드가 발생할 수 있습니다.) 이 문제를 완전히 방지하려면 kubernetes의 kubelet에서 cpu-cfs-quota를 비활성화하거나 container의 limit설정을 하지 않을 수도 있습니다. 하지만 이 경우에 throttling은 발생하지 않지만, container에서 사용하는 cpu의 limit이 사라지는 의미이므로 모니터링에 좀 더 주의해야 합니다.
또한 CPU 자원 최적화를 위해 병렬성 설정을 살펴볼 수 있습니다. container는 worker node의 os kernel을 공유하기 때문에 CPU core 개수를 worker node의 cpu core개수와 동일하다고 인식합니다. 즉, 자기가 모두 사용할 수 있다고 생각합니다. 그렇기 때문에 병렬성 설정이 cpu core개수에 연동되어 있다면 과부화, cpu throttling이 생기기 쉽습니다.
다음으로 CPU 자원 할당량을 최적화하는 방안에 대해 생각해보려 합니다. CPU Requests와 Limits를 적절히 설정하는 방법으로 흔히 Right sizing이라고 합니다. 할당량이 부족하면 서비스가 불안정하고, 할당량이 과하다면 불필요한 비용이 발생합니다. 이에 안정성과 효율성 사이에서 균형을 지킬 수 있는 정책을 사용해야 할 것입니다.
예를 들면 대고객 서비스와 직접 연관된 workload에 대해서는 requests를 하루 최대 사용량 * 2로 설정하고 limits는 설정하지 않을 수 있고, 그렇지 않은 나머지 서비스에 대해서는 requests를 하루 최대 사용량과 비슷하게, limits는 조금 더 설정할 수 있습니다.
사실 클라우드 상에서의 부하는 auto scaling이라는 마법같은 방법을 통해 부하가 많은 경우 대응을 잘 할 수 있기에 고민이 필요할까싶지만, auto scaling이 되는 조건이라던지 생각해볼 부분이 많은 것 같습니다.
클라우드 상의 인프라는 on-demand로 배포되다 보니 오버 provisioning이 일어나면 즉시 비용이 낭비되게 됩니다. 그래서 할당 최적화를 민첩하게 하여 비용을 최적화해야 합니다.
신규 서비스의 경우 처음에는 작은 리소스를 가진 ec2나 vm을 사용하다가 서비스 규모가 커짐에 따라 사이즈를 늘려가야 하는데 이 때 늘리는 비율이 적절하지 않으면 리소스 파편화가 일어나게 되며 효율적으로 비용 관리를 할 수 없게 됩니다.

위 그림을 보면 4 Core CPU, 16GB Memory의 EC2를 가정하고 Pod A가 Pod B가 CPU는 4개를 모두 사용하고 Memory는 6기가만 사용한다면 CPU는 모두 사용하고 있어 해당 EC2에 더 이상 Pod를 배포할 수 없지만, Memory는 10기가가 낭비되게 됩니다. 이러한 상황이 리소스 파편화가 발생했다고 할 수 있습니다.
이러한 경우에는 EC2의 타입을 변경하거나 사이즈 변경을 통해 해결할 수 있을 것 같습니다.
상황을 가정해 보겠습니다. 한 클러스터에 다양한 Pod를 배치해야 하며, 해당 Pod가 필요한 리소스는 아래와 같습니다.
- PodA: 1 vCPU, 2 GiB 메모리
- PodB: 2 vCPU, 4 GiB 메모리
- PodC 4 vCPU, 8 GiB 메모리
총 워크로드는 10개의 PodA (10 vCPU, 20 GiB), 5개의 PodB (10 vCPU, 20 GiB), 1개의 PodC (4 vCPU, 8 GiB) = (전체 요구 리소스: 24 vCPU, 48 GiB). 사용하는 워커노드의 인스턴스 유형은 m5시리즈를 사용한다고 할 때, 적절히 업스케일링된 유형과 그렇지 않은 유형을 사용했을 때 비용 차이를 분석해보려 합니다.
- 적절한 스케일업이 이루어지지 않은 경우
- m5.xlarge 인스턴스 유형을 사용한 경우 (4 vCPU, 16 GiB)
- 하나의 인스턴스에 배치할 수 있는 Pod구성: PodA 4개, 또는 PodB 2개 등
- 전체 워크로드를 수용하기 위해 총 7개의 m5.xlarge instance필요 = 비용 $ 0.248 X 7개 = 시간당 $ 1.736
- Pod의 배포 순서는 랜덤하다고 가정하고 최악의 경우 7개 필요
- 적절한 스케일업이 이루어진 경우
- m5.2xlarge 인스턴스 유형을 사용한 경우 (8 vCPU, 32 GiB)
- 하나의 인스턴스에 배치할 수 있는 Pod구성: PodA 8개, 또는 PodB 4개 등
- 전체 워크로드를 수용하기 위해 총 3개의 m5.2xlarge instance필요 = 비용 $ 0.496 X 3개 = 시간당 $ 1.488
| 전략 | 인스턴스 구성 | 총 vCPU | 총 메모리 | 낭비한 리소스 | 총 비용 (시간당) |
| m5.xlarge 사용 | 7 X m5.xlarge | 28 vCPU | 112 GiB | 4 vCPU, 64GiB | $ 1.736 |
| m5.2xlarge 사용 | 3 X m5.2xlarge | 24 vCPU | 96 GiB | 0 vCPU, 48 GiB | $ 1.488 |
극단적인 예시를 들었다고 볼 수 있지만, 이처럼 효과적인 비용 관리를 할 수 있으니 클러스터 규모 증가에 따라 업스케일링이 적절히 이루어진다면, 운영의 효율성 뿐만 아니라 비용 효율화도 가져올 수 있습니다.
또한 추가적으로 kuberentes에서는 daemonset이라고 하는 모든 워커노드에 동일하게 뜨는 csi, cni, kube-proxy등의 고정적으로 리소스를 사용하는 서비스들이 많이 존재합니다. 클러스터의 규모가 커지면서 내부 워커 노드의 스펙이 그것에 맞게 잘 커지지 않으면 daemonset이 사용하는 리소스의 비율만 증가하고 각 EC2의 실제 개발한 서비스들이 사용하는 리소스의 비율이 줄어들게 됩니다. 이에 클러스터 규모가 커짐에 따라 적절히 워커 노드의 스펙을 늘려준다면 리소스 파편화도 줄일 수 있고 daemonset의 사용 비율이 줄어들면서 전체적으로 봤을 때 워커 노드의 개수가 확연히 줄어들 수 있습니다.
예를 들어 워커 노드를 네배 정도 스케일업함에 따라 전체 워커 노드의 개수가 40% 감소하는 효과가 생길 수 있음에 이로써 발생하는 비용적 이득을 잘 고려하여 노드 스펙을 설정해야 할 것 같습니다.
마지막으로 CPU부하 분산이 있을 것 같습니다. 노드 별로 리소스 사용의 괴리가 발생할 수 있는데 이는 예를 들어 비슷한 시간대 가장 많은 부하를 받는 노드와 적게 받는 노드의 차이가 40%가 차이가 나는 경우는 특정 노드의 과부하로 인해 전체 서비스의 지연이 발생할 수 있다는 것입니다.
이는 Pod Scheduler분배의 문제가 있을 수 있는데, 보통 Pod가 어떤 노드에 배포될 지를 결정하기 위해서 labeling, NodeSelector, Taint/Toleration을 사용하여 필터링을 하게 됩니다. 다음 단계로 워커 노드의 유후 리소스와 Pod가 필요한 리소스를 스코어링해서 가장 적절한 워커 노드에 배치하게 됩니다. 이렇게 되면 리소스 관점에서는 적절한 분배이지만 부하 관점에서는 고려하지 않은 스케줄링이라고 할 수 있습니다. 즉, 같은 시점에 피크 트래픽을 받는 서비스들이 한 워커 노드에 몰릴 가능성이 생깁니다.
이를 위해 Kubernetes의 Topology Spread Constraint를 활용할 수 있습니다. 이를 활용하면 특정 서비스 군들을 같은 라벨이나 같은 조건으로 묶어서 모든 노드에 같은 개수로 분배시킬 수 있습니다. 이를 통해 고가용성과 효율적인 리소스 활용의 이점을 가질 수 있습니다. 이러한 설정만을 통해 괴리율을 어느정도 줄일 수 있습니다.
https://kubernetes.io/docs/concepts/scheduling-eviction/topology-spread-constraints/
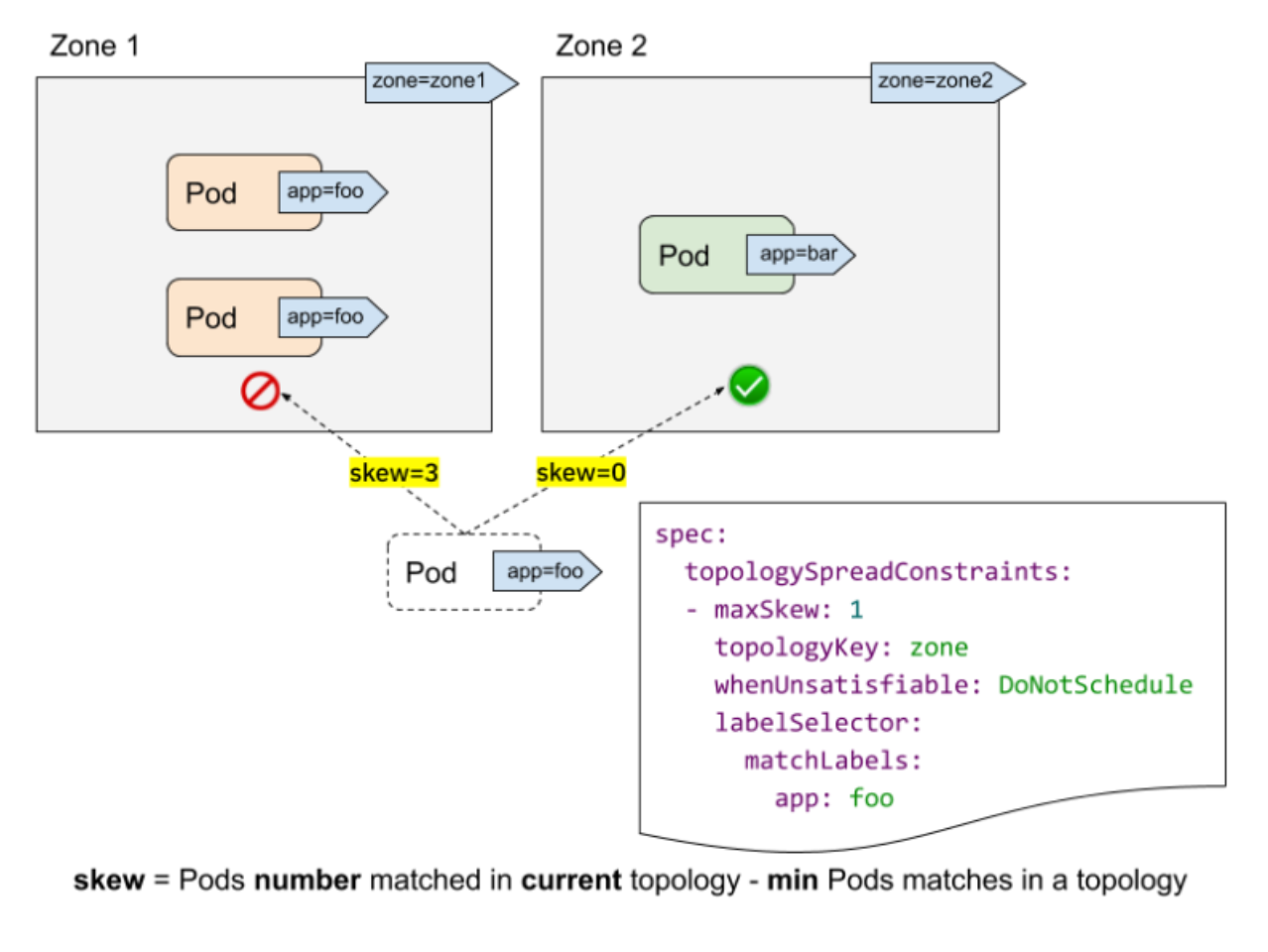
긴 글을 통해 CPU를 알뜰하게 사용하는 방법에 대해 알아봤습니다. 요약하자면 아래와 같으며 긴 글 읽어주셔서 감사합니다. 이 글은 SLASH24의 https://toss.im/slash-24/sessions/28 를 보고 작성한 글입니다. 감사합니다.
- CPU Requests / Limits Right Sizing을 통해 오버프로비저닝 방지
- 노드 스펙을 업스케일링하여 리소스 파편화 방지
- 모니터링 툴의 불필요한 연산을 줄이고, 모니터링 아키텍처를 개선하여 CPU사용량 최소화
- Topology Aware를 통해 CPU사용량을 골고루 분산
'DevOps' 카테고리의 다른 글
| DevOps에서 참고하면 좋은 리눅스 커널 정보 확인 (1) (2) | 2024.12.10 |
|---|---|
| GCP 네트워크 트래픽 전달 과정 (0) | 2024.11.28 |
| azure & github certification (0) | 2024.11.08 |
| AWS와 Azure (1) | 2024.11.01 |
| 클라우드 관련 업무 지식 (0) | 2024.09.23 |
