
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- terraform
- Deployment
- EC2
- asgi
- leetcode
- asyncio
- ansible
- Role
- Kubernetes
- docker
- Django
- IAC
- ebs
- AZ-104
- AZURE
- RBAC
- K8S
- 자바스크립트
- Network
- AZ-900
- dockerfile
- elasticsearch
- EKS
- FastAPI
- AWS
- Service
- IAM
- DevOps
- Python
- POD
- Today
- Total
궁금한게 많은 개발자 노트
[ ES ] Elasticsearch의 구성 요소 본문

Elasticsearch에 대해서는 한번 정리한 적이 있으며 RDBMS와의 차이점과 필요성에 대해 정리하였습니다.
다시 한번 Elasticsearch에 대해 간략히 알아보면 Elasticsearch는 Apache Lucene(아파치 루씬: 정보 검색 라이브러리) 기반 java 오픈 소스 분산 검색 엔진입니다.
HTTP 웹 인터페이스와 스키마에서 자유로운 JSON 문서와 함께 분산 멀티테넌트(하나의 소프트웨어 인스턴스로 여러 사용자에게 서비스를 제공) 지원 전문 검색 엔진을 제공합니다.
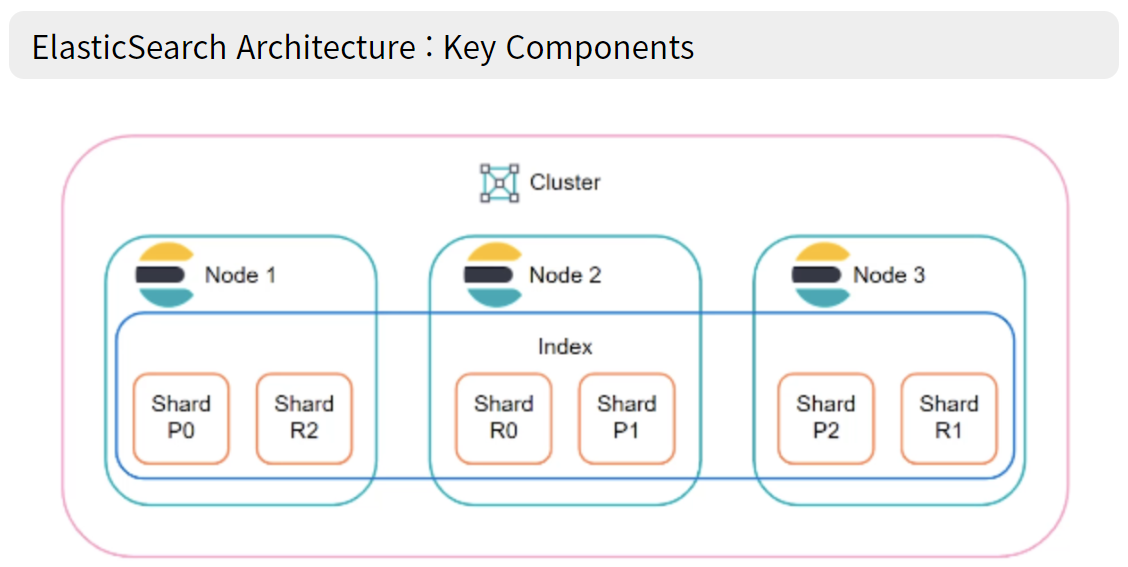
Elasticsearch의 구성 요소로는 크게 Cluster와 Node로 구분지을 수 있습니다.
Cluster는 하나 이상의 노드의 집합으로 모든 노드를 포괄하는 통합 색인화 및 검색 기능을 제공합니다.
(Elasticsearch System에서 가장 큰 단위) Cluster는 고유한 이름으로 식별되며 (default: elasticsearch), 해당 이름을 통해 노드가 클러스터의 구성원이 될 수 있습니다.
Node를 그냥 두지 않고, Cluster로 구성한다는 것은 Cluster에 포함된 Node들의 관리가 필요하다는 것을 의미합니다.
작은 규모의 Cluster에서는 각각의 Elasticsearch Node가 모든 기능을 담당해도 괜찮지만, 대규모 Cluster의 경우에는 각 Node들이 데이터, 마스터, 코디네이팅 등의 역할을 나누어 맡도록 하는 것이 관리 측면이나 하드웨어 스펙 관련 비용 등을 고려하였을 때 효율적입니다.
# Cluster는 여러 서버에 바인딩 될 수 있으며, 반대로 하나의 서버에서 여러 Cluster를 운영할 수 있습니다.

https://www.elastic.co/guide/en/elasticsearch/reference/7.16/modules-node.html
Node | Elasticsearch Guide [7.16] | Elastic
Master nodes must have a path.data directory whose contents persist across restarts, just like data nodes, because this is where the cluster metadata is stored. The cluster metadata describes how to read the data stored on the data nodes, so if it is lost
www.elastic.co
Node는 Elasticsearch를 구성하기 위한 하나의 Instance를 의미합니다. Node는 Cluster의 고유한 이름을 통해 Cluster에 포함될 수 있으며 원하는 개수의 노드를 포함할 수 있습니다.
주요 Elasticsearch의 Node의 기능들은 다음과 같습니다.
- Master Node
- Data Node
- Ingest Node
- Tribe Node
- Coordinating only Node (Client Node)

Mater eligible Node
이름에서 유추할 수 있듯 Master가 될 수 있는 노드를 의미하며 Cluster에 속한 Node들을 관리하는 역할을 담당합니다.
여러 Node가 Master가 될 수 있는 후보로 Cluster를 구성할 수는 있지만 하나의 Master Node가 선출되어 동작하며, 해당 Node가 역할 수행을 할 수 없을 경우 Master Node후보 중 한 Node가 Master Node가 됩니다.
소규모 Cluster의 경우 Master Node가 Data Node역할을 함께 담당할 수 있지만 대규모의 경우 고가용성을 보장하기 위해 최소 3개의 Master eligible Node를 구축하는 것을 추천합니다. 마스터 후보 노드들은 처음부터 마스터 노드와 클러슽터 메타 데이터를 공유하기에 마스터 노드가 문제가 생기더라도 바로 이어 받아 클러스터가 정상 동작할 수 있게 대체됩니다.
Master Node와 Data Node를 분리하게되면 이점은, 클러스터가 커져서 노드와 샤드들의 개수가 많아지게 되면 모든 노드들이 마스터 노드의 정보를 계속 공유하는 것은 부담이 될 수 있습니다. 이때는 마스터 노드의 역할을 수행 할 후보 노드들만 따로 설정해서 유지하는 것이 전체 클러스터 성능에 도움이 될 수 있습니다. Master Node는 데이터 검색이나 인덱싱에 의한 CPU, 메모리, I/O부하에서 벗어나 맡은 역할에만 집중하는 것이 안정적인 클러스터 운영에 도움이 될 것 입니다.
Master Node의 역할로는 아래와 같습니다.
- Cluster 내부 Node의 추적, 관리 (클러스터 정보 관리)
- Index 생성 및 삭제, 메타데이터 관리 (샤드의 위치 등)
- Data 입력 시 어느 Data Node의 Shard에 할당할 지 결정
# Split Brain
마스터 후보 노드를 하나만 구성하게 되면 해당 노드가 유실되었을 경우 클러스터 전체가 동작하지 않습니다. 이에 복수개의 마스터 후보 노드 구성을 추천하는데 3개 이상의 홀수를 추천합니다.
마스터 후보 노드가 2개인 경우, 마스터 후보 노드 사이에 네트워크가 단절된 경우 문제가 발생할 수 있습니다.
이 경우에 각각의 마스터 후보 노드가 마스터 노드로 승격되어 두개의 클러스터를 구성하게 되는데, 이 경우 양쪽 클러스터에 각각 다른 데이터가 추가되거나 업데이트된다면 나중에 네트워크가 복구된 경우 데이터 비동기 문제가 발생합니다. (데이터 무결성 파괴) 이러한 문제를 Split Brain이라고 칭합니다.

이를 방지하기 위해 마스터 후보 노드를 3개 이상으로 두고 한 클러스터에 마스터 후보 노드가 2개 이상인 경우에만 클러스터가 동작하고 그렇지 않은 경우 클러스터는 동작을 멈추도록 해야합니다. 재 연결이 된 경우 변경된 데이터에 대해서만 멈춰있던 클러스터의 데이터 노드에 업데이트해주면 정상 동작이 가능합니다.
클러스터 당 바람직한 마스터 후보 노드의 최소 개수 설정은 (전체 마스터 후보 노드 / 2 ) + 1입니다.
Data Node
Data Node도 마찬가지로 이름에서 유추할 수 있듯, 물리적으로 데이터를 저장하는 노드입니다.
Indexing된 Data를 저장하는 역할(색인)을 담당하며, CRUD작업과 검색 및 집계와 같은 데이터 관련된 역할을 담당합니다.
이러한 작업에는 CPU, 메모리, I/O리소스를 많이 사용하기에 Master Node와 분리하는 것이 안정성 측면에서 도움이 됩니다. 클러스터 관리에서 벗어나 데이터 처리에만 집중할 수 있기 때문입니다.
데이터에도 일종의 Life Cycle이 존재하며, 저장되는 데이터들을 모두 저장하면 좋겠지만 빅데이터의 경우에는 부하가 상당할 것으로 큰 부담입니다. 데이터의 접근 빈도나 중요도에 따라 지속적으로 분석이 필요하고 접근해야하는 경우에는 SSD에 저장해두다가 빈도와 중요도가 낮아지면 하드디스크로 옮기는 것이 비용적으로도 효율적일 것 입니다.
이러한 것을 지원해주는 Elasticsearch의 기능이 ILM(Index Lifecycle Management)입니다.
(data_hot/data_warm/data_cold로 나누어 관리합니다.)
Index
Node에 데이터가 저장되며 이를 Index라고 부릅니다. 각 인덱스는 한개 혹은 여러개의 샤드로 구성됩니다.
그렇다면 인덱스와 샤드는 어떤 것을 의미할까요? Elasticsearch에서는 단일 데이터 단위를 도큐먼트라고 부릅니다.
이러한 도큐먼트들의 집합을 인덱스라고 부르며, 용어상 데이터 저장 단위는 인디시즈(indicies)라고 표현합니다.
인덱스의 개념을 테이블로 볼 수 있으며, RDB에서 데이터를 모아둔 것이 테이블이라면 ES에서 데이터(도큐먼트)를 모아둔 것이 인덱스입니다. 인덱스는 기본적으로 샤드 단위로 분리되고 각 노드에 도큐먼트를 분산하여 저장합니다.
클러스터가 있는 경우 샤드는 여러 노드에 분산될 수 있습니다. (기본적으로 하나의 서버에 한 노드가 매핑 - 저장되는 인덱스를 여러 샤드로 분산시키고, 그 샤드를 클러스터 내 여러 노드에 배치하여 분산 검색)

Shard
인덱스의 도큐먼트를 분산 저장하는 저장소입니다. 위에서 언급했듯 인덱스는 한개 이상의 샤드로 구성됩니다.
인덱스를 생성할 때만 샤드의 개수를 지정할 수 있고, 지정된 개수만큼 노드에 분산하여 저장소를 만들게 됩니다. 그 이후 도큐먼트들은 순차적으로 샤드에 분산 저장되게 됩니다. (샤드는 루씬 라이브러리의 단일 검색 인스턴스입니다)
# 샤드의 개수는 인덱스 생성 시에만 지정 가능하고, 재 색인(저장)하지 않는 이상 변경할 수 없습니다
Primary Shard & Replica
인덱스를 생성할 때 별도 설정을 하지 않으면, ES 7.0버전부터는 디폴트로 1개의 샤드로 인덱스가 구성됩니다. 클러스터에 노드를 추가하게 되면 샤드들이 각 노드들로 분산되고, 디폴트로 1개의 복제본을 생성합니다.
노드가 1개만 존재하는 경우에는 복제본(replica)를 생성하지 않습니다. 그러한 이유로 아무리 작은 클러스터라 할지라도 ES에서는 가용성과 무결성을 위해 최소 3개의 노드로 클러스터를 구성할 것을 권장합니다.
샤드와 복제본은 동일한 데이터를 담고 있으며, 반드시 서로 다른 노드에 저장됩니다. 처음 생성된 노드를 Primary Shard라 부르고 복제본을 Replica라 부릅니다. (복제본은 프라이머리 샤드의 개수만큼 생성)
레플리카를 프라이머리 샤드와 같은 노드에 존재할 수 없으므로, 노드 하나가 죽어도 다른 노드에 있는 복제본 데이터를
제공하여 장애 복구(fail-over)에 도움을 줄 수 있습니다.
노드 하나가 사라지게 되면, 다시 복제본과 프라이머리 샤드를 생성하여 최초 샤드 구성과 동일하게 유지합니다.
(프라이머리 샤드가 유실되면, 복제본이 프라이머리 샤드로 승격되고 새로 복제본 생성)
이를 통해 노드가 유실 되어도 데이터를 잃어버리지 않고, 데이터의 가용성과 무결성을 보장할 수 있습니다.
# 레플리카를 늘리면 저장 성능은 낮아지지만, 읽기 성능이 높아집니다. (줄이면 저장 성능은 좋아지지만, 읽기 성능 저하)
Ingest Node
도큐먼트의 가공과 정제를 위한 인제스트 파이프라인(Ingest Pipeline)이 실행되는 노드입니다.
모든 노드는 기본적으로 인제스트 노드 역할을 수행할 수 있지만, 데이터 처리량이 많은 클러스터를 구축하는 경우 별도의 인제스트 전용 노드를 구성하는 것이 좋습니다.
인제스트 노드의 역할은 데이터가 저장되기 전에 전처리를 통해 원하는 방식으로 데이터를 변형해 저장합니다.
Ingest Node는 데이터를 가공하고 정제한다는 의미에서 Logstash의 기능과 비슷할 수 있습니다. 실제로 Elasticsearch에 데이터를 저장한다는 관점에서 Logstash의 Fliter Plugin과 인제스트 파이프라인의 프로세스가 비슷합니다. 하지만 인제스트 노드를 별도로 가지는 이점으로는 분산 처리가 가능합니다. (Logstash는 단일 노드에서 동작)
그러므로, 데이터의 양이나 노드 스펙을 고려해서 Ingest Node를 구축하는 것도 큰 이점을 가질 수 있습니다.

Client Node (Coordinating only Node)
Coordinating only node를 사용했을 때 장점으로는 data node는 데이터 관리 및 인덱싱에만 집중할 수 있고, Master node는 클러스터 관리에만 집중할 수 있습니다. 즉, Master, Data, Ingest Node가 본연의 역할에만 집중할 수 있게 도움을 주는 노드입니다.
사용자의 요청(REST API요청)이 오면 Load Balancer역할을 하여 사용자가 Aggregation쿼리를 보내면, 필요한 data node에 적절하게 요청을 분산하고 이를 취합해 aggregation을 수행하는 역할을 합니다. 이렇게 되면 data node는 indexing 와중에 간단한 search쿼리만 처리하게 되어 data node의 부하가 줄어듭니다.
즉 코디네이팅 노드가 사용자의 요청을 받아 각 노드들에 전달하고 취합해 결과를 제공하게 됩니다. 코디네이팅 전용 노드를 두게 되면 로드밸런싱, Request 라우팅, Request 캐싱, 각 노드에서 계산된 결과 취합에 집중합니다.
이에 따라 앞에서 언급했듯 데이터 노드의 부하가 줄어들고 검색 효율을 개선할 수 있습니다.

색인(저장)을 빠르게 하기 위해서, 검색을 빠르게 하기 위해서는?
샤드를 너무 잘게 나누게 되면 세그먼트를 만들며 부하를 증가시킵니다. 샤드 수가 증가하면 CPU에서 그만큼 많은 Thread를 사용하여 검색하게 되므로 CPU부하가 증가합니다.
샤드 크기는 20GB ~ 40GB가 적당하다고 합니다. 또한 노드에 저장할 수 있는 샤드의 개수는 가용합 힙의 크기와 비례합니다. 이에 노드에 설정한 힙 1GB당 20개의 샤드가 적당하다고 합니다. (그보다 적은 것을 추천)
(샤드가 많아질 수록 마스터 노드의 부하가 증가하고, 그로 인해 색인과 검색 작업이 느려질 수 있고, 샤드의 크기가 증가하면 장애 발생 시 복구 작업에 부정적인 영향을 끼칠 수 있습니다.)
ex) Heap크기 32GB인 경우 최대 600개 정도의 샤드 구동 가능
추가로, 샤드의 크기를 작게하여 잘게 나누면 여러 노드에 분산되어 검색 시 응답 시간은 더 빨라집니다.
레플리카 관점에서 본다면, 위에서 언급했듯 레플리카의 개수를 늘리면 읽기 성능은 좋아지지만 동시에 쓰기 성능은 낮아짐을 의미합니다. 복제본을 여러개 만들기 위해서는 그만큼 문서 색인(저장)시 쓰기 작업도 복제본의 개수만큼 증가하기 때문입니다.
전체 색인을 빠르게 하려면 하나의 큰 도큐먼트를 입력하는 것을 여러 개의 인덱스로 나누어 분산처리가 가능하도록 하면 색인 속도를 개선시킬 수 있습니다.
정확히 인덱스 개수와 비례하는 것은 아니지만 그에 상응하여 색인 속도가 개선될 수 있습니다.
[ ES 구성 요약 ]

이상으로 Elasticsearch의 구성요소에 대해 알아봤습니다. 내용에 대한 피드백은 언제나 환영합니다. 감사합니다 🙌✔
'DevOps' 카테고리의 다른 글
| [ Docker ] docker image 원격 서버로 전달 (0) | 2023.08.30 |
|---|---|
| [ ES ] Elasticsearch Heap memory 크기 설정 (0) | 2023.08.04 |
| [ IaaS ] Infrastructure as a Code(IaC)란? (0) | 2023.07.28 |
| [ k8s ] Statefulset과 Deployment의 차이점 (0) | 2023.07.20 |
| [ Dockerfile ] RUN, CMD, ENTRYPOINT 차이점 (0) | 2023.07.19 |
