

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- K8S
- Kubernetes
- Service
- AZ-104
- Role
- dockerfile
- terraform
- Deployment
- RBAC
- Django
- AZ-900
- FastAPI
- Network
- DevOps
- AZURE
- leetcode
- EC2
- POD
- 자바스크립트
- ebs
- Python
- ansible
- EKS
- IAM
- docker
- IAC
- asyncio
- elasticsearch
- AWS
- asgi
- Today
- Total
궁금한게 많은 개발자 노트
[ k8s ] pod, deployment, service 본문
Pod란?
kubernetes에서 생성하고 관리할 수 있는 배포 가능한 가장 작은 컴퓨팅 단위입니다.
하나 이상의 컨테이너 그룹이며, 이 그룹은 스토리지 및 네트워크를 공유하고, 해당 컨테이너를 구동하는 방식에 대한 명세를 가집니다. Pod의 Contents는 항상 함께 배치되고 스케줄되며 shared context에서 실행됩니다.
Pod내부에는 컨테이너들의 설정에 사용되는 초기화 컨테이너가 포함될 수 있습니다. 초기화 컨테이너는 완료를 목표로 실행되며 각 초기화 컨테이너는 다음 초기화 컨테이너가 시작되기 전에 완료되어야 합니다.
(초기화 컨테이너 역할: resource limit, volume, security settings를 포함한 셋팅)
Pod의 shared context는 linux의 namespace, cgroup, docker container를 격리하는 것과 같이 잠재적으로 다른 격리 요소.
Pod의 context내에서 개별 application들은 추가적으로 하위 격리가 적용.
Docker 개념 측면에서, 파드는 공유 namespace와 공유 파일시스템 볼륨이 있는 도커 컨테이너 그룹과 비슷합니다.
Pod내 Container는 IP와 Port를 공유합니다. 즉 두개 이상의 Container가 하나의 Pod를 통해 배포되엇을 때 localhost로 통신이 가능합니다. 또한 Container간에는 network namespace와 disk volume을 공유합니다. 일반적으로 application과 log수집기가 다른 container라면 컨테이너 사이에서 격리가 이루어지므로 log수집기가 application container로그 파일을 읽는 것이 불가능하지만, kubernetes의 pod내부에서는 컨테이너끼리 volume을 공유하기에 가능합니다.
또한 Volume은 Pod와 같은 수명을 가집니다. 그것이 의미하는 것은 특정 Pod가 존재하는 한 Volume도 존재함을 의미합니다. 동일한 대체 Pod가 생성되더라도, Volume도 폐기되고 새로 생성됩니다.
Pod 특성
- 기본적으로 하나의 파드에는 하나 이상의 컨테이너가 포함된다. 필요에 따라 하나의 파드에 여러 컨테이너를 포함시킬 수 있다.
- 파드는 노드 IP와 별개로 고유 IP를 할당 받으며, 파드 안의 컨테이너들은 그 IP를 공유한다.
- 파드 자체는 일반적으로 1개의 IP만 가진다. (단, Multus CNI 이용 등 특정 조건에 한해 2개의 IP를 가질 수도 있다.)
- 파드 안의 컨테이너들은 동일한 볼륨과 연결이 가능하다.
- 파드는 클러스터에서 배포의 최소 단위이고, 특정 네임스페이스(Namespace) 안에서 실행된다.
- 파드는 기본적으로 반영속적(ephemeral)이다.
# Pod의 Lifecycle
| Pending | 파드가 쿠버네티스 클러스터에서 승인되었지만, 하나 이상의 컨테이너가 설정되지 않았고 실행할 준비가 되지 않았다. 여기에는 파드가 스케줄되기 이전까지의 시간 뿐만 아니라 네트워크를 통한 컨테이너 이미지 다운로드 시간도 포함된다. |
| Running | 파드가 노드에 바인딩되었고, 모든 컨테이너가 생성되었다. 적어도 하나의 컨테이너가 아직 실행 중이거나, 시작 또는 재시작 중에 있다. |
| Succeeded | 파드에 있는 모든 컨테이너들이 성공적으로 종료되었고, 재시작되지 않을 것이다. |
| Failed | 파드에 있는 모든 컨테이너가 종료되었고, 적어도 하나 이상의 컨테이너가 실패로 종료되었다. 즉, 해당 컨테이너는 non-zero 상태로 빠져나왔거나(exited) 시스템에 의해서 종료(terminated)되었다. |
| Unknown | 어떤 이유에 의해서 파드의 상태를 얻을 수 없다. 이 단계는 일반적으로 파드가 실행되어야 하는 노드와의 통신 오류로 인해 발생한다. |
참고: 파드가 삭제될 때, 일부 kubectl 커맨드에서 Terminating 이 표시된다. 이 Terminating 상태는 파드의 단계에 해당하지 않는다. 파드에는 그레이스풀하게(gracefully) 종료되도록 기간이 부여되며, 그 기본값은 30초이다.
강제로 파드를 종료하려면 --force 플래그를 설정하면 된다.
Deployment
kubernetes공식 docs에서는 deployment는 pod와 replicaset에 대한 선언적 업데이트를 제공한다고 정의합니다.
kubernetes운영 환경에서는 replicaset을 YAMl파일로 직접 사용하는 경우는 없고, 대부분 replicaset과 pod를 정의하는 deployment라는 object를 YAML파일로 정의해서 사용합니다.
즉, replicaset을 이용하여 pod를 업데이트하고 이력을 관리하여 rollback하거나 특정 version으로 돌아갈 수 있습니다.
Deployment를 생성하면 해당 Deployment에 대응하는 Replicaset도 함께 생성됩니다. Replicaset을 사용하지 않고 Deployment를 이용하는 이유는 application의 업데이트와 배포를 편하게 관리하기 위함입니다.
Replicaset은 정해진 수의 동일한 Pod가 항상 실행되도록 관리하며, 노드 장애 등의 이유로 Pod를 사용할 수 없다면 다른 노드에서 Pod를 다시 생성합니다. 즉, 안정적으로 Pod를 관리해줍니다.
Deployment = Replicaset + Pod + History
Replicaset은 Relica-controller의 상위 호환으로 둘 다 Pod가 죽었을 때 다시 복구해주는 역할을 수행합니다.
Replica-controller는 관리할 Pod를 selector를 직접 사용해서 선택하고, replicaset은 matchlabels를 사용하여 관리합니다.
Replicaset = 관리할 Pod를 선택하기 위한 matchlabels + 관리할 pod의 복제본 수 + 관리할 Pod 명세
즉, Deployment를 통해 Pod 가용성을 보장해주며 Pod관리를 추상화 할 수 있게 되었습니다. (Update 및 Scaling의 기능)
Service
Pod집합에서 실행중인 애플리케이션을 네트워크 서비스로 노출하는 추상화 방법
(서비스(Service)는 파드들을 통해 실행되고 있는 애플리케이션을 네트워크에 노출(expose)시키는 가상의 컴포넌트)
쿠버네티스를 사용하면 익숙하지 않은 서비스 디스커버리 메커니즘을 사용하기 위해 애플리케이션을 수정할 필요가 없습니다. 쿠버네티스는 파드에게 고유한 IP 주소와 파드 집합에 대한 단일 DNS 명을 부여하고, 그것들 간에 로드-밸런스를 수행할 수 있게 해줍니다. (eks에서는 ingress ALB를 통해 service사용)
Pod가 외부와 통신할 수 있도록 클러스터 내부에서 고정적인 IP를 갖는 서비스(Service)를 이용: (단일한 네트워크 진입점을 부여)
Pod의 논리적 집합과 그것들에 접근할 수 있는 정책을 정의하는 추상적 개념
Port를 외부로 노출하여 다른 Deployment의 Pod들이 내부적으로 접근하려면 Service Object가 필요합니다.
역할로는 고유한 도메인 이름을 부여하여 entrypoint의 역할을 수행하며, load balancer의 역할도 수행합니다.
Service 유형 https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types
Service
Expose an application running in your cluster behind a single outward-facing endpoint, even when the workload is split across multiple backends.
kubernetes.io
풀어서 설명하면, Pod의 경우 지정되는 IP가 랜덤하고 재 생성될 경우 고정 IP가 아닐 수 있기에 고정된 end point로 호출이 어렵습니다. 또한 여러 Pod에 같은 application이 운용될 경우 load balancing을 지원해줘야하는데 이러한 역할을 Service가 수행합니다.
서비스는 지정된 IP로 생성이 가능하고, 여러 Pod를 묶어서 로드 밸런싱이 가능하며, 고유한 DNS이름도 가질 수 있습니다.
추가로 서비스는 동시에 여러 개의 port를 지원할 수 있습니다.
1. ClusterIP (기본 형태)
ClusterIP는 파드들이 클러스터 내부의 다른 리소스들과 통신할 수 있도록 해주는 가상의 클러스터 전용 IP다. 이 유형의 서비스는 <ClusterIP>로 들어온 클러스터 내부 트래픽을 해당 파드의 <파드IP>:<targetPort>로 넘겨주도록 동작하므로, 오직 클러스터 내부에서만 접근 가능하게 된다. 쿠버네티스가 지원하는 기본적인 형태의 서비스다.
(클러스터 IP(내부 IP)를 할당하므로 클러스터 내에서는 서비스에 접근이 가능하지만 외부에서는 접근X)
Selector를 포함하는 형태
spec.selector에서 지정된 레이블로 여러 파드들이 존재할 경우, 서비스는 그 파드들을 외부 요청(request)을 전달할 엔드포인트(endpoints)로 선택하여 트래픽을 분배하게 된다. 이를 이용하여 한 노드 안에 여러 파드, 또는 여러 노드에 걸쳐 있는 여러 파드에 동일한 서비스를 적용할 수 있다.
Selector가 제외된 형태
필요에 따라 엔드포인트(Endpoints)를 수동으로 직접 지정해줘야 할 때가 있다. 테스트 환경과 상용 환경의 설정이 서로 다르거나, 다른 네임스페이스 또는 클러스터에 존재하는 파드와의 네트워크를 위해 서비스-서비스 간의 연결을 만들어야 하는 상황 등이 있다.
이런 경우에는 spec.selector 없이 서비스를 만들고, 해당 서비스가 가리킬 엔드포인트(Endpoints) 객체를 직접 만들어 해당 서비스에 맵핑하는 방법이 있다.
2. NodePort
NodePort는 외부에서 노드 IP의 특정 포트(<NodeIP>:<NodePort>)로 들어오는 요청을 감지하여, 해당 포트와 연결된 파드로 트래픽을 전달하는 유형의 서비스 (NAT컨셉). 이때 클러스터 내부로 들어온 트래픽을 특정 파드로 연결하기 위한 ClusterIP 역시 자동으로 생성된다.
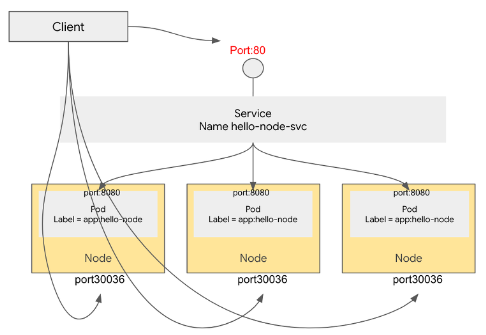
3. LoadBalancer
별도의 외부 로드 밸런서를 제공하는 클라우드(AWS, Azure, GCP 등) 환경을 고려하여, 해당 로드 밸런서를 클러스터의 서비스로 프로비저닝할 수 있는 LoadBalancer 유형도 제공된다.
이 유형은 서비스를 클라우드 제공자 측의 자체 로드 밸런서로 노출시키며, 이에 필요한 NodePort와 ClusterIP 역시 자동 생성된다. 이때 프로비저닝된 로드 밸런서의 정보는 서비스의 status.loadBalancer 필드에 게재된다.
이렇게 구성된 환경에서는, 외부의 로드 밸런서를 통해 들어온 트래픽이 서비스의 설정값을 따라 해당되는 파드들로 연결된다. 이 트래픽이 어떻게 로드 밸런싱이 될지는 클라우드 제공자의 설정에 따르게 된다.
4. ExternalName
서비스에 selector 대신 DNS name을 직접 명시하고자 할 때에 쓰인다. spec.externalName 항목에 필요한 DNS 주소를 기입하면, 클러스터의 DNS 서비스가 해당 주소에 대한 CNAME 레코드를 반환하게 된다. kube-dns 컴포넌트로 DNS를 활용
'DevOps' 카테고리의 다른 글
| [ k8s ] Service YAML 작성 (0) | 2023.02.07 |
|---|---|
| [ k8s ] Deployment YAML (0) | 2023.02.07 |
| [ AWS ] ECR이란? (0) | 2023.02.05 |
| [ AWS ] Auto Scaling Group (0) | 2023.01.25 |
| [ AWS ] Elastic Load Balancing (0) | 2023.01.10 |

